
Coffea framework 와 CMS 의 NanoAOD type DY process 샘플을 가지고
Electron pair 을 selection 하여 Z boson mass peak 을 reconstruction 하는 튜토리얼이다.
[Jupyter notebook 링크] 와 함께 이 글을 보기를 추천한다.
이 튜토리얼은 Coffea 를 이용해서 data analysis 를 하는 Flow 를 설명하기 위해 Jupyter notebook 으로 interactive 한 방법으로 작성되었다.
하지만 실전에서는 대용량의 데이터를 다루기 때문에, 램 용량의 한계로 interative 방법은 못 쓰고, processor 라는 coffea 에서 제공하는 다른 방식을 사용하게 된다. processor 는 차후에 #2 advanced 포스팅 에서 다루겠다.
#1 필요한 라이브러리를 import 해준다.
import awkward as ak
from coffea.nanoevents import NanoEventsFactory, NanoAODSchema
import numpy as np
import matplotlib.pyplot as plt현재 coffea version 은 0.7.2, awkward version 은 1.2.2 이다.
#2 FILE I/O, 이벤트를 읽어들인다.
infile = "YOUR DATA"
dataset="YOUR DATASET"
year='2018'
events = NanoEventsFactory.from_root(infile, schemaclass=NanoAODSchema).events()
isData = "genWeight" not in events.fields
events 를 출력시키면 총 이벤트 갯수 ( 249,779개 ) 를 확인할 수 있다.
해당 데이터는 249,779회의 LHC 가속기 proton-proton 충돌데이터 이고, 각 충돌 이벤트를
array 형태로 저장하고 있다.
events.fields 함수로 각 이벤트에 있는 sub-array (branch라 부른다) 로 접근 할 수 있다.
예를 들어 각 이벤트의 Electron 의 PT 를 보고싶다면 아래와 같이 한다.

총 2차원 array 이다.
해석 하자면, 첫번째 충돌 이벤트에는 총2개의 Electron 이 있고 각각 30.8 GeV 와 29.2 GeV 의 pt 를 가진다.
마지막 충돌 이벤트에는 총2개의 Electron 이 있고 각각 40.5 GeV 와 34.5 GeV 의 pt 를 가진다.
각 이벤트의 Electron 들은 PT 순으로 정렬되어있는것을 짐작할 수 있다.
(하지만 이 부분은 명확하게 하기위해 따로 정렬 렬해주는 코드 블록을 만드는것을 추천한다)
data 의 경우 mc 와 다르게 events.fields 에 'genWeight' 라는 branch 가 없다.
이를 이용해서 isData 라는 boolean type 의 array 를 만들 수 있다.
data 와 mc 를 따로 처리하는 케이스가 종종 생기므로 해당 boolean array 가 유용하게 사용될것이다.
자.. 이제부터 pandas 와 numpy와 거의 똑같은 방식으로 array 갖고놀 수 있다.
#3 유용한 함수의 정의
# << Sort by PT helper function >>
def sort_by_pt(ele,pho,jet):
ele = ele[ak.argsort(ele.pt,ascending=False,axis=1)]
pho = pho[ak.argsort(pho.pt,ascending=False,axis=1)]
jet = jet[ak.argsort(jet.pt,ascending=False,axis=1)]
return ele,pho,jet
events.Electron, events.Photon, events.Jet = sort_by_pt(
events.Electron, events.Photon, events.Jet
)나는 유용한 함수들 (helper function) 들을 여기 정의해뒀다.
본 예제에서는 각 Event 의 object 들 (particle 들) 을 PT 순으로 정렬하는 함수만 사용한다.
#4 Good-Run 체크 ( data 일 경우에만 )
from coffea import lumi_tools
# Golden Json file
if (year == "2018") and isData:
injson = "data/json/Cert_314472-325175_13TeV_Legacy2018_Collisions18_JSON.txt.RunABD"
if isData:
lumi_mask_builder = lumi_tools.LumiMask(injson)
lumimask = ak.Array(
lumi_mask_builder.__call__(events.run, events.luminosityBlock)
)
events = events[lumimask]Data cleaning using Coffea framework in CMS
Coffea Framework 을 이용해서, CMS data분석을 하는중에, 문서화가 너무 안 되어있어서 가장 처음으로 하는겸, 내가 잊어버리지 않으려고 정리를 시작한다. 가장 첫 번째로, 어떻게 Golden Json File 을 이
jwcorp.tistory.com
data 일 경우 Golden json file 을 이용하여 GoodRun 인 event 만선택을 한다.
본 예제는 mc 로 진행하여 해당 스텝은 패스했다.
#5 Trigger 적용
# Trigger set
doubleelectron_triggers ={
'2018': [
"Ele23_Ele12_CaloIdL_TrackIdL_IsoVL", # Recomended
]
}먼저 사용할 Trigger 리스트를 dictionary 형태로 저장한다.
연도 별로 다를 수 있고, 같은 연도에도 여러개의 Trigger 가 동시에 적용될 수 있다.
지금은 편의상 하나의 연도, 하나의 Trigger 만 고려하겠다.

events.HLT 로 사용 가능한 Trigger 들의 정보에 접근할 수 있다.
fields 를 이용해서 사용 가능한 Tirgger 리스트를 볼 수 있다.
우리가 사용할 "Ele23_Ele12_CaloIdL_TrackIdL_IsoVL" tigger 를 인덱스로 주면 각 이벤트가 해당 Trigger 를 통과 했는지 안 했는지 boolean type 의 array 로 표현되어있다.
# double lepton trigger
is_double_ele_trigger=True
if not is_double_ele_trigger:
double_ele_triggers_arr=np.ones(len(events), dtype=np.bool)
else:
double_ele_triggers_arr = np.zeros(len(events), dtype=np.bool)
for path in doubleelectron_triggers[year]:
if path not in events.HLT.fields: continue
double_ele_triggers_arr = double_ele_triggers_arr | events.HLT[path]double electron Trigger 를 사용 할 경우,
double_ele_triggers_arr 란 변수에 각 이벤트가 Trigger 를 통과했는지 안 했는지에 관한 boolean array 를 저장한다.
여러 Trigger 를 사용할 것을 대비해서, for loop를 돌면서 zeros array 에 or operator 로 더해가는 방식을 사용했다.
(보통 여러 Trigger 를 동시에 고려할 때, and 를 사용하지않고 or 를 사용한다)
# Sort particle order by PT # RunD --> has problem
events.Electron,events.Photon,events.Jet = sort_by_pt(events.Electron,events.Photon,events.Jet)
# Apply trigger
Initial_events = events
events = events[double_ele_triggers_arr]
print("Events passing triggers and skiimig: ",len(events) )사전 정의했던 sorting function 을 사용하고, Tirgger mask 를 적용한다.
events = events[mask] 형태로, mask 는 boolean array 이기 때문에 True 인 event 만 살아남아서 events 에 저장된다.
Trigger 를 통과한 이벤트개수를 출력한다.
나같은 경우 원래 이벤트 249,779 개에서 216,549 개로 줄어들었다.
#6 Object selection
이제 본격적으로 입자를 선택해서 analysis 를 진행해보겠다.
본 예제는, Z 로 부터 나온 Electron, Positron 을 선택하여, Lorentz sum을 한 후, Z boson 의 mass 를 reconstruction 하는 내용이다.
Electron = events.Electron
EleSelmask = (
(Electron.pt >= 10)
& (np.abs(Electron.eta + Electron.deltaEtaSC) < 1.479)
& (Electron.cutBased > 2)
& (abs(Electron.dxy) < 0.05)
& (abs(Electron.dz) < 0.1)
) | (
(Electron.pt >= 10)
& (np.abs(Electron.eta + Electron.deltaEtaSC) > 1.479)
& (np.abs(Electron.eta + Electron.deltaEtaSC) <= 2.5)
& (Electron.cutBased > 2)
& (abs(Electron.dxy) < 0.1)
& (abs(Electron.dz) < 0.2)
)
Electron = Electron[EleSelmask]Electron 에 관한 정의를 한다.
Detector 가 완벽하게 Electron만을 잡아내지 못하기 때문에,
간단한 momentum 과 geometry 에 관한 cut이 들어 가야한다.
EgammaPOG 에서 추천하는 cut 을 넣었고, 역시 boolean type 의 mask 로 정의하여 Electron array 에 적용하였다.
mask 를 적용한 Electron 만이 진정한 Electron 이다.
# apply cut 2
Diele_mask = ak.num(Electron) == 2
Electron = Electron[Diele_mask]
events = events[Diele_mask]
print(len(events))위에서 정의한 Electron 이 정확히 2개인 이벤트만을 선택한다.
이 조건을 담은 mask 를 Diele_mask 라 정의했고,
Electron 과 events array 에 각각 적용한다.
이미 Electron array는 cut 이 적용됐는데 왜 다시 적용하는지 헷갈릴 수 있다.
Electron array는 2차원으로 Coffea 에서 2차원 array 에 masking 을 하면 차원이 줄지 않고 Null 이 생긴다.
따라서 Null 값을 없애려면 다시 Diele_mask 를 적용해야한다.
이부분은 따로 포스트를 만들어서 심도있게 다뤄보겠다. 일단 여기서는 위처럼 해야한다는것만 알아두자
남은 이벤트의 개수를 출력하면 216,549 -> 165,812
#7 Event selection
지금까지 Electron을 정의하고, 2개의 Electron 이 있는 이벤트를 골라내었다.
이제, Z 로부터 나온 Electron 을 골라내야 하는데, 간단히 charge 가 서로 반대인 Electron pair 를 Z 에서 나온 Electron 이라고 가정하고 진행하겠다.
먼저, 각 이벤트의 Electron 을 따로 분리해야 한다.

각 event 의 Electron 을 PT 순으로 정렬 했으므로,
Electron[:,0] 는 두 Electron 중에 PT 가 큰 leading Electron array 가 되고
Electron[:,1] 는 PT 가 두 번째로 큰 subleading Eledctron array가 된다.
이 둘을 더하면, sclar sum이 아닌 Lorentz Vector sum을 하게된다.
Lorentz Vector sum 후 mass 함수로 쉽게 두 Electron 의 invariant mass 를 구할 수 있다.
중요한 특징으로는, Electron[:,0] 과 Electron[:,1] 은 Electron 과 다르게 1차원 array이다.
diele = Electron[:,0] + Electron[:,1]
# OSSF
ossf_mask = (diele.charge == 0)
# Z mass window
Mee_cut_mask = diele.mass > 10
# Electron PT cuts
Elept_mask = (Electron[:,0].pt >= 25) & (Electron[:,1].pt >= 10)
# MET cuts
# Mask
Event_sel_mask = Elept_mask & ossf_mask & Mee_cut_mask
이를 바탕으로, opposite charge 의 Electron pair 가 있는 event 만을 골라낸다.
추가 적으로 각 Electron 의 PT, Electron pair 의 invariant mass cut 을 적용하였다.
1차원 array 끼리의 연산이므로 특별히 차원에 관하여 신경 쓸 필요가 없다.
diele = diele[Event_sel_mask]
Electron = Electron[Event_sel_mask]
events = events[Event_sel_mask]
print(len(events))Event selection 또한 boolean type array mask 방식을 사용한다.
Event_sel_mask 가 Event selection 을 통과했는지 안 했는지에 관한 boolean array 이다.
이제 diele 는 우리가 원하는 이벤트중에 Electron pari 의 Lorentz Vector array
Electron 은 우리가 원하는 이벤트중에서의 Electron
events 는 우리가 원하는 이벤트이다
최종적으로 남은 이벤트수는 165812개이다.
#8 Visualize results (1) matplotlib
이제 diele.mass 를 histogram 으로 시각화해서 Z 보손의 mass인 91 GeV 근방에 peak 이 생기는지 확인해보자.
먼저 python 의 matplotlib 과 plot style 을 CMS와 ROOT format 으로 바꿔주는 mplhep 라이브러리를 사용해봤다.
def draw(arr, title, start, end, bin): # Array, Name, x_min, x_max, bin-number
# ROOT-like format
plt.style.use(hep.style.ROOT)
plt.figure(figsize=(8, 8)) # Figure size
bins = np.linspace(start, end, bin) # divide start-end range with 'bin' number
binwidth = (end - start) / bin # width of one bin
# Draw histogram
plt.hist(arr, bins=bins, alpha=0.7, label=title) # label is needed to draw legend
plt.xticks(fontsize=16) # xtick size
plt.xlabel(title, fontsize=16) # X-label
# plt.xlabel('$e_{PT}',fontsize=16) # X-label (If you want LateX format)
plt.ylabel("Number of Events/(%d GeV)" % binwidth, fontsize=16) # Y-label
# plt.ylabel('Number of Events',fontsize=16) # Y-label withou bin-width
plt.yticks(fontsize=16) # ytick size
plt.grid(alpha=0.5) # grid
plt.legend(prop={"size": 15}) # show legend
# plt.yscale('log') # log scale
#outname_fig = title + ".png"
#plt.savefig(outname_fig)
plt.show() # show histogram
plt.close()
draw(diele.mass,"z-peak",0,200,100)
91 GeV 근방에서 peak 을 확인 할 수 있다.
plot style 을 보면 기본 matplotlib 과는 tick 등이 다르다.
mplHEP 으로 HEP 에서 주로 쓰는 ROOT 라는 프레임워크 스타일로 맞춰놨다.
( 공식 발표나 까다로운 미팅에서는 HEP에서 사용해왔떤 프레임워크 처럼 안 보이면 태클 걸린다.. )
#9 Visualize results (2) coffea
이번에는 coffea 내부의 기능으로 visualize 를 해 보겠다.
실전에서 coffea 를 쓸 때에는 interactive 모드가 아닌 processor 모드로 돌리게 되는데,
이 때에는 이 방법을 할 수 없이 써야한다.
import coffea.hist as hist
histo = hist.Hist("Counts",
hist.Cat("dataset", "dataset"),
hist.Bin("zmass", "zmass", 100, 0, 200),
)hist 를 import 한다.
matplotlib 과 다르게 먼저 histogram 형태를 정의한다.
이유는 빅데이터를 처리할 때에는 Loop 를 돌면서 histogram 에 데이터를 Fill 하기 때문이다.
Coffea histogram 은 다차원의 Axes 가 존대한다.
따라서 z mass 라는 histogram 하나에, Signal region 의 Z mass Control region 의 Z mass, 다른 여러가지 dataset 의 Z mass 를 전부 저장할 수 있다. 이것은 Coffea histogram 에만 있는 최대 장점이다.
먼저 여러가지 dataset 이 있다고 가정하여 'dataset' 이란 카테고리를 만든다
그리고 zmass array 를 넣기 위해 bins xmin xmax bin을 만든다.
histo.fill(dataset='dataset',zmass=diele.mass)이제 히스토그램에 diele.mass array 를 fill 한다.
plt.rcParams["figure.figsize"] = (8,8)
hist.plot1d(histo['dataset'])
plt.title('Z-peak',fontsize=20)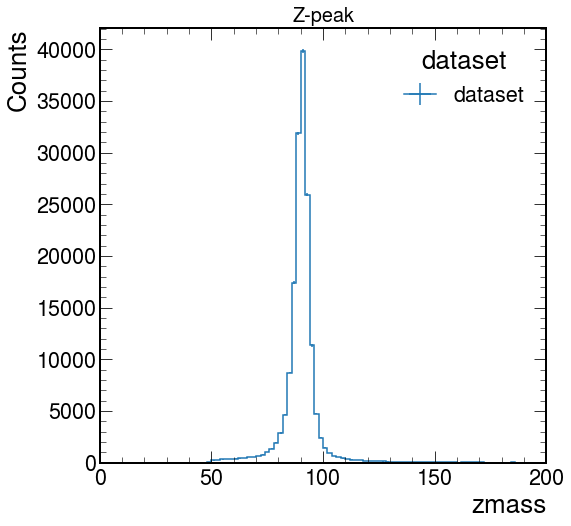
hist.plot1d 함수로 똑같은 histogram 을 확인할 수 있다.
첨부된 [Jupyter notebook 링크] 에는 multi-dimension axes 를 활용하여,
Signal region 과 Control region 의 zmass 를 그리는 예제도 추가했다.
'대학원 생활' 카테고리의 다른 글
| HEP04 columnar database in HEP (0) | 2022.03.31 |
|---|---|
| CMS01: 2016 pre-VFP vs post-VFP (0) | 2021.12.10 |
| HEP03 Reconstruct Z boson using Coffea #2 Processor (0) | 2021.12.10 |
| HEP01 Data cleaning using Coffea framework in CMS (1) | 2021.07.17 |



