
급속 근황 전개가 되었다. 박사 졸업을 하고 바로 운용사에서 퀀트, 정확히 말하면 인공지능 투자 알고리즘 업무를 맡게 되었다. 열심히 하면 고민거리가 한 번에 해결된다던데 진짜였다. 하지만 자유의 시간은 짧았고 회사에서 업무는 매우 속도가 빨랐다. 제한 시간이 짧았고 성과가 확실해야 한다. 첫 2주는 새로 공모하는 AI 펀드에 들어갈 알고리즘을 설계하는 업무를 맡았고, 이제는 해당 알고리즘 유지보수와 향후 알고리즘 고도화에 대한 업무를 맡았다. 하다 보니 알고리즘 설계는 아이디어가 꽤나 잘 떠올랐지만 코딩 구현 쪽에서 많은 어려움을 겪었다. 그래서 블로그에 직접 찾아봤던 코드들을 아카이빙 하면서 역량을 강화해야겠다는 생각이 들었다. 내가 GPT로 검색해서 짜는 코드를 누구는 머릿속에서 그냥 외워서 짠다. 분발하자.
오늘 살펴볼 내용은 벡테스팅을 최적화 하는 방법이다. 퀀트 엔진 즉 "알파"라고 불리는 시장 초과 수익률 알고리즘을 찍어내는 공장을 만들려면 백테스팅을 사람이 일일이 하면 안 된다. 자동화가 필요하고 단순한 랜덤 자동화보다는 똑똑하게, 최적해를 찾아가는 알고리즘을 적용해야 한다. AI 연구를 하던 사람으로서 이는 딥러닝 모델을 Hyper parameter최적화 툴로 튜닝을 하는 작업과 유사하게 다가왔다. 즉 내 아이디어는 Hyper parameter 최적화 알고리즘을 그대로 백테스팅에 사용해 보자 이다.
정말 단순한 예로 골드크로스 데드크로스 전략이 있다. 해당 백테스팅은 backtrader, backtesting.py 로 구현할 수 있고 예제는 많이 있으니 자세한 설명은 생략하겠다. 문제는 여기서 두 파라미터가 존재한다. 바로 장기 mva 단기 mva를 각가 며칠로 잡을까이다. 2개의 자유도가 있는 문제를 목표 함수가 최대가 되게끔 푸는 optimization 문제로 정의할 수 있다. 여기서 목표함수는 sharp ratio 로 정의했다.
from datetime import datetime
import backtrader as bt
import yfinance as yf
import optuna
import matplotlib.pyplot as plt
# SmaCross 전략 파트이다. Backtrader 에서 흔히 쓰는 클래스이다.
class SmaCross(bt.Strategy):
params = dict(
pfast=5, # fast moving average period
pslow=30 # slow moving average period
)
def __init__(self):
sma1 = bt.ind.SMA(period=self.p.pfast)
sma2 = bt.ind.SMA(period=self.p.pslow)
self.crossover = bt.ind.CrossOver(sma1, sma2)
def next(self):
if not self.position: # not in the market
if self.crossover > 0: # if fast crosses slow to the upside
#self.buy(size=1)
self.buy(size=1)
elif self.crossover < 0: # in the market & cross to the downside
self.close() # close long position
# 목적 함수 정의 -> 이 목적함수를 인풋으로 넣으면 optuna가 알아서 최적화 해준다.
def objective(trial,data):
# Optuna를 통해 최적화할 파라미터 선택한다. 실제로 pfast, pslow 값이 리스트로 들어가는건 아니고
# 여기서 랜덤으로 하나의 값이 선택되어 들어간다. 랜덤으로 샘플링하는 방식은 optuna의 최적 알고리즘에 따라 달려있다.
# 사실 이렇게 카테고리컬로 정의하는게 맞다
#pfast = trial.suggest_categorical('pfast', [2,5,10,20])
#pslow = trial.suggest_categorical('pslow', 30,60,100,200,252])
# 하지만 알고리즘이 너무 쉬운 문제를 풀게하면 안 되니까 서칭 스페이스를 크게했다.
pfast = trial.suggest_int('pfast', 5,20,step=1)
pslow = trial.suggest_int('pslow', 30,252,step=1)
# Backtrader 의 흔한 세팅이다
cerebro = bt.Cerebro(stdstats=False)
cerebro.adddata(data)
cerebro.broker.setcash(10000.0)
cerebro.broker.setcommission(0.002)
cerebro.addstrategy(SmaCross, pfast=pfast, pslow=pslow)
cerebro.addanalyzer(bt.analyzers.SharpeRatio, _name='mysharpe', riskfreerate=0.01)
# backtrader의 흔한 전략 실행 방식이다.
results = cerebro.run()
final_value = cerebro.broker.getvalue()
sharpe_ratio = results[0].analyzers.mysharpe.get_analysis()['sharperatio']
return sharpe_ratio # 최대화/최소화 할 값을 return 하게 해야한다.
# 데이터 로딩
data = bt.feeds.PandasData(dataname=yf.download('SPY', '2018-01-01', '2024-03-31'))
# Optuna 최적화 실행
# 이 단계에서 최적화 방식을 정할 수 있다. TPE는 Bayesian optimization 을 사용한다.
study = optuna.create_study(direction='maximize',sampler=optuna.samplers.TPESampler())
#study = optuna.create_study(direction='maximize',sampler=optuna.samplers.RandomSampler())
study.optimize(lambda trial : objective(trial, data), n_trials=100)
# 최적화 결과 출력
print('Best trial:')
trial = study.best_trial
print(f"pfast: {trial.params['pfast']}, pslow: {trial.params['pslow']}")
print(f"Best Sharpe Ratio: {trial.value}")
# Optuna 튜닝 결과 시각화
fig_param_importances = optuna.visualization.plot_param_importances(study)
fig_optimization_history = optuna.visualization.plot_optimization_history(study)
fig_contour = optuna.visualization.plot_contour(study, params=['pfast', 'pslow'])
fig_param_importances.show()
fig_optimization_history.show()
fig_contour.show()
# 기본 세팅과 비교
data = bt.feeds.PandasData(dataname=yf.download('SPY', '2018-01-01', '2024-03-31'))
cerebro = bt.Cerebro(stdstats=False)
cerebro.adddata(data)
cerebro.broker.setcash(10000.0)
cerebro.broker.setcommission(0.002)
#cerebro.addstrategy(SmaCross, pfast=trial.params['pfast'], pslow=trial.params['pslow'])
cerebro.addstrategy(SmaCross)
cerebro.addanalyzer(bt.analyzers.SharpeRatio, _name='mysharpe', riskfreerate=0.01)
results = cerebro.run()
sharpe_ratio = results[0].analyzers.mysharpe.get_analysis()['sharperatio']
print(f"Human set: {sharpe_ratio}")
#cerebro.plot(iplot=False, volume=False)
TPE를 사용한 결과이다. 15 trial 만에 -1.19의 sharp를 얻었다. 당연하겠지만 이렇게 단순히 설계한 골드크로스 데드크로스 전략이 잘 먹힐 리가 없다. 상대 비교에만 집중해 보자.
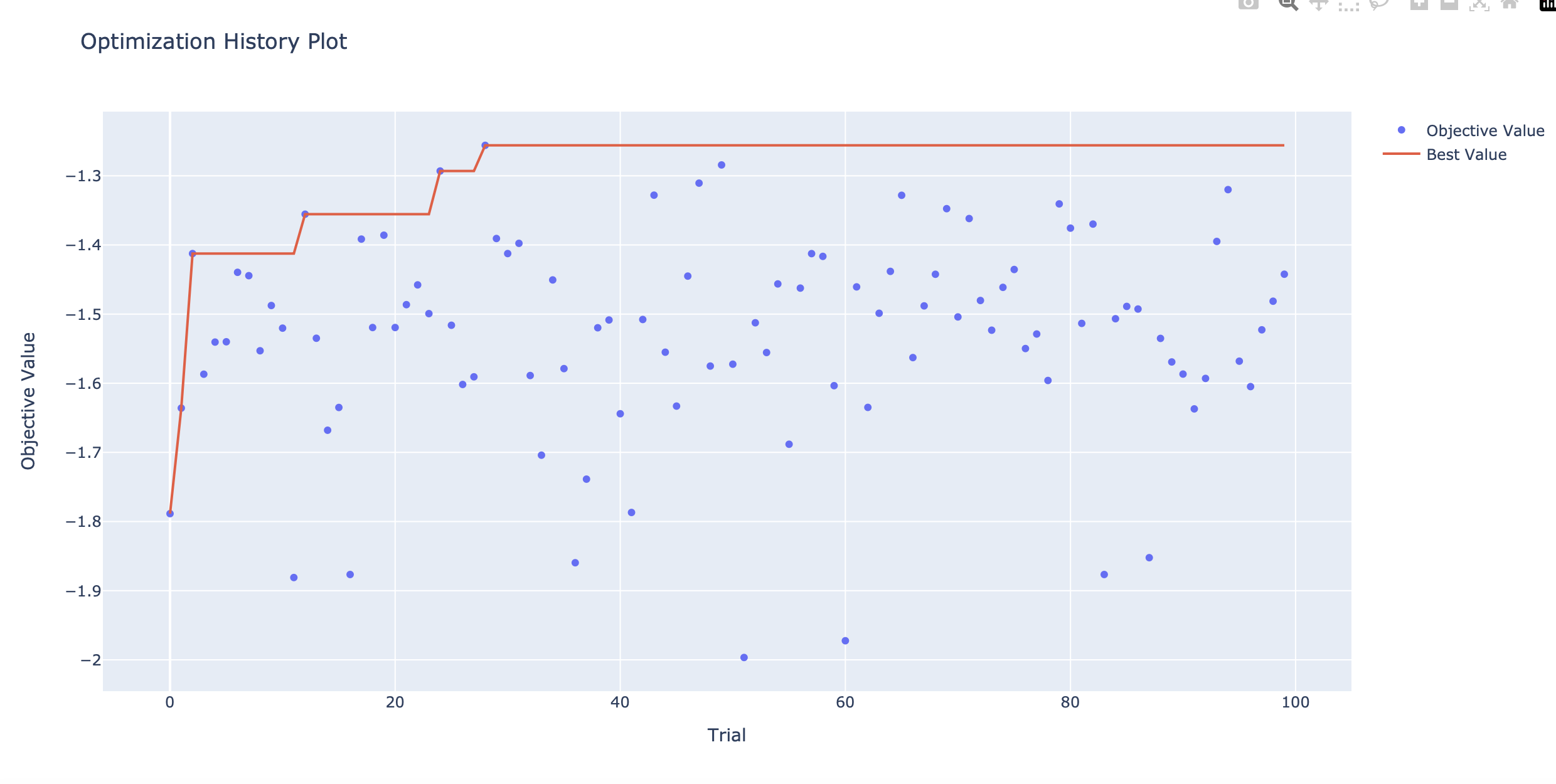
랜덤서치의 경우 28 trial 만에 -1.25를 얻었다. TPE가 속도면에서, 성능면에서 랜덤서치를 능가하는 것을 확인했다. (당연한 결과이다.)
Optuna의 최신 알고리즘에 대한 내용은 이 블로그에 잘 나와있다. https://www.nielsvandervelden.com/blog/2022-02-09-optuna-samplers/
Optuna Samplers | Niels van der Velden
Optimizing ML models using Optuna Samplers
www.nielsvandervelden.com
오늘 실험은 퀀트 전략 백테스팅을 하나의 머신러닝 모델로 생각하고 hyper parameter 툴을 적용해 보는 것이다. 예상대로 효과가 있었고 실제로 머신러닝을 돌리는 것보다 시간이 덜 걸려서 더 다양한 시도를 해볼 수 있을 것 같다.
'투자' 카테고리의 다른 글
| 트레이딩1. 델타헤징 수익 원리 : 하락장에서도 돈 버는 법 (5) | 2024.11.10 |
|---|---|
| 클하대학교 - 현실화된 인플레이션과 투자전략 정리 (0) | 2022.06.20 |
| 데이터의 편향 (Narrative & Numbers) (0) | 2022.04.30 |
| 근황, 산업스터디 (Feat 비상금의 중요성) (2) | 2022.04.26 |
| 퀀트킹 백테스터04 피터린치 전략 (0) | 2022.02.26 |



